Local Ai LLM
4.2


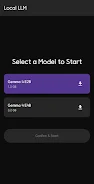
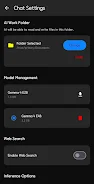
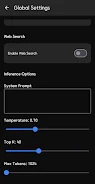



Local Ai LLM is a powerful on-device AI assistant that runs entirely on your smartphone without routing data through cloud servers, giving you a private, offline-capable companion for writing, file work, and device control. It uses advanced Gemma 4 models locally so you can generate text, analyze documents and images, or ask the assistant to operate apps and settings while keeping conversations and files stored only on your device. If privacy, offline access, and direct file manipulation matter, Local Ai LLM offers a practical way to use cutting-edge language models without exposing your data to external servers.
⭐ Complete offline operation and local data storage so chats, attachments, and search history never leave your device.
⭐ Local Ai LLM runs Gemma 4 models (E2B, E4B) on-device, using GPU/NPU acceleration for faster text generation without cloud latency.
⭐ AI agent controls phone functions by voice or text: open apps, toggle flashlight, report battery level and interact with installed apps.
⭐ Work Folder lets the assistant read, create, edit, and delete files in a designated directory to support document editing and coding tasks.
⭐ Attach photos or upload PDFs, DOCX, XLSX for analysis and summaries, and optionally enable real-time web search to fetch current information.
✅ Strong privacy: all processing and storage happen on-device so sensitive data stays local.
✅ Usable offline for travel or areas without connectivity; switch web search on only when needed.
✅ Highly configurable inference settings (system prompt, temperature, top-k, max tokens) for power users.
✅ Organized chat and folder management keeps conversations and projects tidy for repeated use.
✅ Utilizes device GPU/NPU acceleration for more responsive performance on modern smartphones.
❎ Initial model download requires 1.5–3.2GB of space and is best done on stable Wi-Fi.
❎ Performance and response speed depend on your phone’s RAM and processor; older devices may be slower.
❎ Generating responses uses significant device resources and can increase battery drain during heavy use.
Local Ai LLM requires an initial model download (approximately 1.5GB–3.2GB) and supports Gemma 4 E2B and E4B variants; install over reliable Wi-Fi and expect faster performance on devices with dedicated GPU/NPU acceleration.























